AXI(Advanced eXtensible Interface) 学习笔记(二)
AXI(Advanced eXtensible Interface) 学习笔记(二)
Tim Dong6 请求属性
本章介绍了指示下游组件应如何处理请求的请求属性。本章包含以下小节:
- 从设备类型
- 内存属性
- 内存类型
- 协议错误
- 内存保护与领域管理扩展
- 内存加密上下文
- 多区域接口
- 服务质量(QoS)信令
6.1 从属类型
从属设备分为内存从属设备或外设从属设备两类。
内存从属设备
内存从属设备需正确处理所有事务类型。
外设从属设备
外设从属设备具有实现定义的访问方式。通常,访问方式在组件数据手册中进行定义,该手册会描述该从属设备能正确处理的事务类型。
对于外设从属设备,任何不属于其实现定义的访问方式的访问,都必须按协议规范完成。但在发生此类访问后,不要求该外设从属设备继续正常运行,仅要求其继续以符合协议的方式完成后续事务。
6.2 内存属性
本节描述的属性决定了缓存、缓冲区和内存控制器等系统组件应如何处理请求。
AWCACHE和ARCACHE信号指定请求的内存属性。它们控制:
- 事务在系统中的处理流程。
- 任何系统级缓冲区和缓存对事务的处理方式。
在本规范中,术语AxCACHE统称AWCACHE和ARCACHE信号。下表描述了AWCACHE和ARCACHE信号。
| 名称 | 宽度 | 默认值 | 描述 |
|---|---|---|---|
| AWCACHE、ARCACHE | 4 | 0x0 | 请求的内存属性控制事务在系统中的处理流程以及缓存和缓冲区对请求的处理方式。 |
CACHE_Present属性用于确定接口上是否存在AxCACHE信号。
| CACHE_Present | 默认值 | 描述 |
|---|---|---|
| True | Y | 存在AWCACHE和ARCACHE。 |
| False | 不存在AWCACHE和ARCACHE。 |
AWCACHE位的编码如下:
• [0] 可缓冲(Bufferable)
• [1] 可修改(Modifiable)
• [2] 其他分配(Other Allocate)
• [3] 分配(Allocate)
ARCACHE位的编码如下:
• [0] 可缓冲(Bufferable)
• [1] 可修改(Modifiable)
• [2] 分配(Allocate)
• [3] 其他分配(Other Allocate)
注意,对于读请求和写请求,分配位(Allocate)和其他分配位(Other Allocate)的位置不同。
6.2.1 可缓冲(Bufferable),AxCACHE[0]
对于写事务:
• 若可缓冲位未置位,写响应表示数据已到达其最终目的地。
• 若可缓冲位置位,当满足可观测性要求时,写响应可从中间节点发送。
对于读事务,当ARCACHE[3:2]未置位(非缓存)且ARCACHE[1]置位(可修改)时:
• 若可缓冲位未置位,读数据必须从最终目的地获取。
• 若可缓冲位置位,读数据可从最终目的地获取,或从正传输至最终目的地的写事务中获取。
对于ARCACHE[3:1]的其他组合,可缓冲位无影响。
6.2.2 可修改(Modifiable),AxCACHE[1]
当AxCACHE[1]置位时,事务为可修改(Modifiable),表示事务的特性可被修改。当AxCACHE[1]未置位时,事务为不可修改(Non-modifiable)。
以下章节描述不可修改事务和可修改事务的属性。
6.2.2.1 不可修改事务
不可修改事务不得拆分为多个事务,也不得与其他事务合并。
在不可修改事务中,下表所示参数不得更改。
| 参数 | 信号 |
|---|---|
| 地址 | AxADDR(因此AxREGION也固定) |
| 大小 | AxSIZE |
| 长度 | AxLEN |
| 突发类型 | AxBURST |
| 保护属性 | AxPROT、AxNSE |
AxCACHE属性仅可修改为将事务从“可缓冲”转为“不可缓冲”,不允许其他任何修改。
事务ID和QoS值可修改。
长度大于16的不可修改事务可拆分为多个事务。每个生成的事务必须满足本小节要求,但以下情况除外:
• 长度被缩减;
• 生成事务的地址被适当调整。
若不可修改事务为独占访问(由AxLOCK置位指示),则在总访问字节数不变的情况下,允许修改大小(AxSIZE)和长度(AxLEN)。
在某些情况下,可能无法满足不可修改事务的要求。例如,当数据宽度缩小到小于大小(Size)所需的宽度时,事务必须被修改。
执行此类操作的组件可选择性包含实现定义的机制,以指示修改已发生。该机制可辅助软件调试。
6.2.2.2 可修改事务
可修改事务可通过以下方式修改:
• 一个事务可拆分为多个事务;
• 多个事务可合并为一个事务;
• 读事务可获取比所需更多的数据;
• 写事务可通过WSTRB信号访问比所需更大的地址范围,以确保仅更新适当的位置;
• 在每个生成的事务中,以下属性可被修改:
– 地址(AxADDR)
– 大小(AxSIZE)
– 长度(AxLEN)
– 突发类型(AxBURST)
以下属性不得更改:
• 独占访问指示(AxLOCK);
• 保护和安全属性(AxPROT和AxNSE)。
AxCACHE可被修改,但任何修改必须确保:不会因阻止事务传播到所需节点,或改变缓存中事务的查找需求,而降低其他组件对事务的可见性。对内存属性的任何修改,必须对同一地址范围的所有事务保持一致。
事务ID和QoS值可修改。
不允许以下事务修改:
• 导致访问与原始事务不同的4KB地址空间;
• 导致对单拷贝原子性大小区域的单次访问被拆分为多次访问。
6.2.3 分配(Allocate)与其他分配(Other Allocate),AxCACHE[2] 和 AxCACHE[3]
若分配位置位:
• 数据可能已被预分配,因此必须在缓存中查找该缓存行。
• 建议将数据分配到缓存中以供未来使用。
若其他分配位置位:
• 数据可能已被预分配,因此必须在缓存中查找该缓存行。
• 不建议分配该数据,因为预计不会再次访问。
若分配位和其他分配位均未置位,则请求无需在任何缓存中查找。
6.3 内存类型
AxCACHE信号的组合表示一种内存类型。下表展示了内存类型的编码。括号中的值允许使用但不推荐。未在表中列出的值为保留值。
| ARCACHE[3:0] | AWCACHE[3:0] | 内存类型 | |
|---|---|---|---|
| 0b0000 | 0b0000 | 设备不可缓冲(Device Non-bufferable) | |
| 0b0001 | 0b0001 | 设备可缓冲(Device Bufferable) | |
| 0b0010 | 0b0010 | 普通不可缓存不可缓冲(Normal Non-cacheable Non-bufferable) | |
| 0b0011 | 0b0011 | 普通不可缓存可缓冲(Normal Non-cacheable Bufferable) | |
| 0b1010 | 0b0110 | 写穿透不分配(Write-Through No-Allocate) | |
| 0b1110 (0b0110) |
0b0110 | 写穿透读分配(Write-Through Read-Allocate) | |
| 0b1010 | 0b1110 (0b1010) |
写穿透写分配(Write-Through Write-Allocate) | |
| 0b1110 | 0b1110 | 写穿透读写分配(Write-Through Read and Write-Allocate) | |
| 0b1011 | 0b0111 | 写返回不分配(Write-Back No-Allocate) | |
| 0b1111 (0b0111) |
0b0111 | 写返回读分配(Write-Back Read-Allocate) | |
| 0b1011 | 0b1111 (0b1011) |
写返回写分配(Write-Back Write-Allocate) | |
| 0b1111 | 0b1111 | 写返回读写分配(Write-Back Read and Write-Allocate) |
内存类型由ARCACHE(读)和AWCACHE(写)的组合定义,核心分类逻辑如下:
设备类(Device)
0b0000/0b0001:用于外设访问,不可缓冲/可缓冲。- 特性:直接访问硬件,不经过缓存(避免数据不一致),可缓冲模式允许中间节点暂存数据以提升效率。
普通不可缓存类(Normal Non-cacheable)
0b0010/0b0011:用于无需缓存的内存区域(如设备寄存器映射)。- 特性:读写直接穿透缓存,可缓冲模式允许写操作在缓冲区暂存。
写穿透类(Write-Through)
- 以
ARCACHE[3]=1(Allocate置位)为主特征,写操作直接更新内存,缓存仅作为副本。 - 分配策略:
No-Allocate(0b1010):读写均不分配缓存(仅查找)。Read-Allocate(0b1110):读时分配缓存,写时不分配。Write-Allocate(0b1010+0b1110):写时分配缓存(适合写后立即读的场景)。Read+Write-Allocate(0b1110+0b1110):读写均分配缓存。
- 以
写返回类(Write-Back)
- 以
ARCACHE[3]=1且ARCACHE[2]=1(Allocate+Other Allocate置位)为主特征,写操作优先更新缓存,仅当缓存行被替换时才写回内存。 - 分配策略:
No-Allocate(0b1011):读写均不分配缓存。Read-Allocate(0b1111):读时分配缓存,写时可能不分配。Write-Allocate(0b1011+0b1111):写时分配缓存。Read+Write-Allocate(0b1111+0b1111):读写均分配缓存(最高效,适合高频读写区域)。
- 以
括号值(兼容性设计)
- 如
ARCACHE=0b1110/AWCACHE=0b0110的组合,允许读写采用不同策略(如读分配、写不分配),提升灵活性。
- 如
内存类型编码的核心是为不同访问场景优化缓存行为:
- 设备类:确保硬件交互的实时性。
- 不可缓存类:避免缓存带来的延迟和数据不一致。
- 写穿透类:在保证数据实时性的同时,利用缓存提升读效率。
- 写返回类:通过减少内存访问次数,最大化提升性能(适合高速数据区)。
通过4位信号组合,系统可针对不同内存区域(如代码段、数据缓冲区、设备寄存器)定制最优的缓存策略。
6.3.1 内存类型要求
本节规定了每种内存类型的必需行为。
6.3.1.1 设备不可缓冲(Device Non-bufferable)
设备不可缓冲内存的必需行为:
• 写响应必须从最终目的地获取。
• 读数据必须从最终目的地获取。
• 事务为不可修改。
• 读数据不得预取。
• 写事务不得合并。
6.3.1.2 设备可缓冲(Device Bufferable)
设备可缓冲内存类型的必需行为:
• 写响应可从中间节点获取。
• 写事务必须及时在最终目的地可见。
• 读数据必须从最终目的地获取。
• 事务为不可修改。
• 读数据不得预取。
• 写事务不得合并。
两种设备内存类型均为不可修改。在本规范中,“设备内存”与“不可修改内存”可互换使用。
对于读事务,设备不可缓冲和设备可缓冲内存类型的必需行为无差异。
6.3.1.3 普通不可缓存不可缓冲(Normal Non-cacheable Non-bufferable)
普通不可缓存不可缓冲内存类型的必需行为:
• 写响应必须从最终目的地获取。
• 读数据必须从最终目的地获取。
• 事务为可修改。
• 写事务可合并。
6.3.1.4 普通不可缓存可缓冲(Normal Non-cacheable Bufferable)
普通不可缓存可缓冲内存类型的必需行为:
• 写响应可从中间节点获取。
• 写事务必须及时在最终目的地可见(定义见术语表)。没有机制可确定写事务何时在最终目的地可见。
• 读数据可从以下任一来源获取:
– 最终目的地。
– 正传输至最终目的地的写事务。
• 若读数据来自写事务:
– 必须来自最新版本的写数据。
– 该数据不得缓存以服务后续读请求。
• 事务为可修改。
• 写事务可合并。
对于普通不可缓存可缓冲读请求,数据可来自仍在传输至最终目的地的写事务。此数据与“读和写事务同时传播到最终目的地”的情况无法区分。以此方式返回的读数据不表示写事务已在最终目的地可见。
6.3.1.5 写穿透不分配(Write-Through No-Allocate)
写穿透不分配内存类型的必需行为:
• 写响应可从中间节点获取。
• 写事务必须及时在最终目的地可见(定义见术语表)。没有机制可确定写事务何时在最终目的地可见。
• 读数据可从中间缓存副本获取。
• 事务为可修改。
• 读数据可预取。
• 写事务可合并。
• 读和写事务均需执行缓存查找。
• “不分配”属性是一种分配提示,即建议内存系统出于性能考虑不为此类事务分配缓存,但不禁止读和写事务的分配。
6.3.1.6 写穿透读分配(Write-Through Read-Allocate)
写穿透读分配内存类型的必需行为与写穿透不分配内存相同。出于性能考虑:
• 建议为读事务分配缓存。
• 不建议为写事务分配缓存。
6.3.1.7 写穿透写分配(Write-Through Write-Allocate)
写穿透写分配内存类型的必需行为与写穿透不分配内存相同。出于性能考虑:
• 不建议为读事务分配缓存。
• 建议为写事务分配缓存。
6.3.1.8 写穿透读写分配(Write-Through Read and Write-Allocate)
写穿透读写分配内存类型的必需行为与写穿透不分配内存相同。出于性能考虑:
• 建议为读事务分配缓存。
• 建议为写事务分配缓存。
6.3.1.9 写返回不分配(Write-Back No-Allocate)
写返回不分配内存类型的必需行为:
• 写响应可从中间节点获取。
• 写事务无需在最终目的地可见。
• 读数据可从中间缓存副本获取。
• 事务为可修改。
• 读数据可预取。
• 写事务可合并。
• 读和写事务均需执行缓存查找。
• “不分配”属性是一种分配提示,即建议内存系统出于性能考虑不为此类事务分配缓存,但不禁止读和写事务的分配。
6.3.1.10 写返回读分配(Write-Back Read-Allocate)
写返回读分配内存类型的必需行为与写返回不分配内存相同。出于性能考虑:
• 建议为读事务分配缓存。
• 不建议为写事务分配缓存。
6.3.1.11 写返回写分配(Write-Back Write-Allocate)
写返回写分配内存类型的必需行为与写返回不分配内存相同。出于性能考虑:
• 不建议为读事务分配缓存。
• 建议为写事务分配缓存。
6.3.1.12 写返回读写分配(Write-Back Read and Write-Allocate)
写返回读写分配内存类型的必需行为与写返回不分配内存相同。出于性能考虑:
• 建议为读事务分配缓存。
• 建议为写事务分配缓存。
6.3.2 不匹配的内存属性
多个从设备访问同一内存区域时,可能使用不匹配的内存属性。但为保证功能正确性,必须遵守以下规则:
• 所有访问同一内存区域的主设备(Manager),必须对该区域在任何层级的可缓存性有一致的视图。需遵循的规则:
– 若地址区域为不可缓存(Non-cacheable),所有主设备必须使用AxCACHE[3:2]均未置位的事务。
– 若地址区域为可缓存(Cacheable),所有主设备必须使用AxCACHE[3:2]中至少有一位置位的事务。
• 不同主设备可使用不同的分配提示(allocation hints)。
• 若目标区域为普通不可缓存(Normal Non-cacheable),任何主设备都可使用设备内存(Device memory)事务访问。
• 若目标区域具有可缓冲(Bufferable)属性,任何主设备都可使用不允许可缓冲行为的事务访问(例如,要求从最终目的地获取响应的事务不允许可缓冲行为)。
6.3.3 更改内存属性
特定内存区域的属性可从一种类型更改为另一种不兼容的类型(例如,从写穿透可缓存(Write-Through Cacheable)更改为普通不可缓存(Normal Non-cacheable))。此类更改需要通过适当的流程执行。
通常执行以下流程:
- 所有主设备停止访问该区域。
- 单个主设备执行所有必要的缓存维护操作。
- 所有主设备使用新属性重启对该内存区域的访问。
6.3.4 事务缓冲
对以下内存类型的写访问不需要从最终目的地获取事务响应,但要求写事务必须及时在最终目的地可见:
• 设备可缓冲(Device Bufferable)
• 普通不可缓存可缓冲(Normal Non-cacheable Bufferable)
• 写穿透(Write-Through)
对于写事务,这三种内存类型要求的行为相同。
对于读事务,要求的行为如下:
• 对于设备可缓冲内存,读数据必须从最终目的地获取。
• 对于普通不可缓存可缓冲内存,读数据可从最终目的地获取,或从正传输至最终目的地的写事务中获取。
• 对于写穿透内存,读数据可从中间缓存副本获取。
除确保写事务及时向最终目的地推进外,中间缓冲区还必须遵循以下行为:
• 能响应事务的中间缓冲区必须确保:随着时间推移,任何对普通不可缓存可缓冲内存的读事务都向其目的地推进。这意味着转发读事务时,尝试转发不得无限期持续,且用于转发的数据不得无限期保留。协议未定义用于转发读事务的数据可保留多久,但在此机制中,读取数据的行为不得重置数据超时周期。
若没有此要求,对同一位置的持续轮询可能会阻止缓冲区中读事务的超时,从而阻碍读事务向目的地推进。
• 能持有并合并写事务的中间缓冲区必须确保:事务不得无限期停留在其缓冲区中。例如,合并写事务不得重置决定写事务何时向最终目的地传输的机制。
若没有此要求,对同一位置的持续写操作可能会阻止缓冲区中写事务的超时,从而阻碍写事务向目的地推进。
有关这些内存类型读访问的必需行为,参考:
• 设备可缓冲
• 普通不可缓存可缓冲
• 写穿透不分配
6.3.5 设备内存类型的示例用法
本规范支持组合使用设备不可缓冲(Device Non-bufferable)和设备可缓冲(Device Bufferable)内存类型,以强制写事务到达其最终目的地,并确保发起的主设备(Manager)知道事务何时对所有其他主设备可见。
标记为设备可缓冲的写事务需要及时到达其最终目的地,但该事务的写响应可由中间缓冲区发出。因此,发起的主设备无法知道写操作何时对所有其他主设备可见。
若主设备先发出一个或一串设备可缓冲写事务,随后发出一个设备不可缓冲写事务,且所有事务使用相同的AXI ID,则AXI的排序要求会强制所有设备可缓冲写事务在设备不可缓冲事务的响应发出前到达最终目的地。因此,设备不可缓冲事务的响应表明所有事务已对所有主设备可见。
设备不可缓冲事务仅能保证与它使用相同ID且指向同一从属设备(Subordinate device)的设备可缓冲事务已完成。
6.4 协议错误
AXI协议定义了两类协议错误:软件协议错误和硬件协议错误。
6.4.1 软件协议错误
当对同一位置的多次访问具有不匹配的可共享性(shareability)或可缓存性(cacheability)属性时,会发生软件协议错误。软件协议错误可能导致一致性丢失,并造成数据值损坏。协议要求,对于软件协议错误,系统不得死锁,且事务必须始终在系统中推进。
某一4KB内存区域中的访问导致的软件协议错误,不得造成另一4KB内存区域中的数据损坏。对于普通内存(Normal memory)中存储的位置,可通过适当的软件屏障(software barriers)和缓存维护操作,使内存位置恢复到确定状态。
访问外设时,若使用了可修改事务(AxCACHE[1]置位),则无法保证外设的正确运行。唯一的要求是,外设需继续以符合协议的方式响应事务。使被错误访问的外设恢复到已知工作状态所需的事件序列,由实现定义(IMPLEMENTATION DEFINED)。
6.4.2 硬件协议错误
硬件协议错误定义为所有非软件协议错误的协议错误。硬件协议错误无需支持。
若发生硬件协议错误,错误恢复无法保证。系统可能崩溃、锁死或出现其他不可恢复的故障。
6.5 内存保护与领域管理扩展(Realm Management Extension)
AXI提供可用于保护内存免受意外事务影响的信号。
内存保护还可通过领域管理扩展(RME)进行扩展。RME提供基于硬件的隔离,允许执行上下文在不同安全状态(Security states)下运行,并共享系统资源。
使用RME时,它会扩展物理寻址和未转换事务的地址空间,影响缓存维护操作的运行,并扩展MPAM信号。
保护信号如下表所示。
| 名称 | 宽度 | 默认值 | 描述 |
|---|---|---|---|
| AWPROT、ARPROT | 3 | - | 请求的访问属性,可用于保护内存免受意外事务的影响。 |
| AWNSE、ARNSE | 1 | 0b0 | 扩展可寻址的物理地址空间,使其包含Root(根)和Realm(领域)空间。 |
PROT_Present属性用于确定接口上是否存在AxPROT信号。
不使用保护属性的从属设备(Subordinate)可在其接口中省略AxPROT输入。
PROT_Present属性如下表所示。
| PROT_Present | 默认值 | 描述 |
|---|---|---|
| True | Y | 存在AWPROT和ARPROT。 |
| False | 不存在AWPROT和ARPROT。 |
使用RME时,RME_Support属性设为True,且接口上存在AxNSE信号。
RME_Support属性如下表所示。
| RME_Support | 默认值 | 描述 |
|---|---|---|
| True | 支持RME,接口上存在所有RME信号。 | |
| False | Y | 不支持RME,接口上不存在任何RME信号。 |
本质是通过基础保护信号(AxPROT)和扩展机制(RME),在硬件层面实现内存访问的安全性和隔离性,适配不同安全等级的系统需求。
保护属性分为三部分。
非特权/特权(Unprivileged / privileged)
AXI主设备(Manager)可能支持多个操作特权级别,并可选择将特权概念扩展到内存访问。
AxPROT[0]标识访问为非特权或特权:
• 0b0:非特权(Unprivileged)
• 0b1:特权(Privileged)
部分处理器支持多级特权,具体与AXI特权级别的映射需参考所选处理器的文档。AXI仅能区分特权访问和非特权访问。
安全属性(Security attribute)
若AXI主设备支持不同的安全操作状态,可通过安全属性将其扩展到内存访问。具有不同安全属性的请求可被视为处于不同地址空间,因此同一地址可能根据安全属性解码到不同位置。
AxPROT[1]和AxNSE信号用于定义安全属性,如下表所示。
| AxNSE | AxPROT[1] | 安全属性 |
|---|---|---|
| 0 | 0 | 安全(Secure) |
| 0 | 1 | 非安全(Non-secure) |
| 1 | 0 | 根(Root) |
| 1 | 1 | 领域(Realm) |
AxNSE信号仅在RME_Support属性为True时存在。若RME_Support为False,则仅可访问安全(Secure)和非安全(Non-secure)地址空间。
指令/数据(Instruction / data)AxPROT[2]指示事务是指令访问还是数据访问:
• 0b0:数据访问(Data access)
• 0b1:指令访问(Instruction access)
AXI协议将此指示定义为提示(hint),并非在所有情况下都准确(例如,事务中混合包含指令和数据项时)。建议主设备将AxPROT[2]置为低电平(LOW)以指示数据访问,除非明确已知为指令访问。
三者共同通过AxPROT信号组实现内存访问的权限、安全域和类型的基础划分,是硬件级访问控制的核心依据。
6.6 内存加密上下文(Memory Encryption Contexts)
内存加密上下文(MEC)是Arm领域管理扩展(RME)的扩展,允许每个领域(Realm)拥有自己独特的加密上下文。MEC扩展将内存加密上下文分配给领域物理地址空间内的所有内存访问。所有内存事务都与一个MECID相关联,该MECID由安全状态、转换机制、转换表和MEC系统寄存器决定。内存加密引擎使用MECID作为加密上下文表的索引(该表包含密钥或调整值),这些上下文参与外部内存加密。
使用MEC有助于保护内存中的领域数据,因为它能使每组领域数据以不同方式加密。这意味着,即使恶意从设备访问物理内存设备并能解密一组领域数据,也无法使用相同的解密方法访问其他组领域数据。在加密点(PoE)之前,组件间传输的数据为明文形式。
R-EL2级别的领域管理软件控制MECID策略及其向领域的分配。
注意:MEC架构规范[3]详细说明了MECID值不匹配时的几种实现选项。本MEC实现假设主设备(Managers)和缓存不执行任何MECID检查。例如,若与某个MECID关联的读访问目标位置在缓存中有副本且该副本与另一个MECID关联,读访问仍会成功,如同MECID值未不匹配一样。此处无需额外保护,因为R-EL2级别的领域管理软件会确保一个上下文无法访问属于另一个上下文的位置,从而防止明文泄露。
6.6.1 MEC信号
MEC_Support属性决定接口是否支持内存加密上下文。
MEC_Support属性如下表所示。
| MEC_Support | 默认值 | 描述 |
|---|---|---|
| True | 支持MEC,存在AxMECID信号。 |
|
| False | Y | 不支持MEC,不存在AxMECID信号。 |
MEC是RME的扩展,因此若RME_Support属性为False,MEC_Support必须为False。
支持MEC需要以下信号:
MECID信号如下表所示。
| 名称 | 宽度 | 默认值 | 描述 |
|---|---|---|---|
| AWMECID、ARMECID | MECID_WIDTH | 全零 | RME内存加密上下文标识符(MECID)。 |
参数MECID_WIDTH定义AxMECID信号的宽度。
MECID_WIDTH属性如下表所示。
| 名称 | 取值 | 默认值 | 描述 |
|---|---|---|---|
| MECID_WIDTH | 0、16 | 0 | AWMECID和ARMECID的位宽。 |
MECID_WIDTH属性需遵循以下规则:
• 若MECID_WIDTH为0,接口上不存在AWMECID和ARMECID。
• 若MEC_Support为False,MECID_WIDTH必须为0。
• 若MEC_Support为True,MECID_WIDTH不得为0。
注意:MECID的宽度不表示组件使用的不同值的数量。通过使用更窄的内部宽度,可能减少MECID的存储需求。
若两个组件间接口的MECID位宽不同,可适当进行零扩展或截断最高有效位。仅当系统中所有支持MEC的组件将公共MECID宽度设置为最小支持宽度时,这种调整才能保证MEC正确运行。
根据MEC_Support属性值,主设备与从属设备接口的兼容性如下表所示。
| 主设备MEC_Support | 从属设备MEC_Support:False | 从属设备MEC_Support:True |
|---|---|---|
| False | 兼容。 | 兼容。AxMECID输入接低电平。 |
| True | 兼容。下游内存不使用MEC加密。 | 兼容。 |
6.6.2 MECID的使用
MECID的值范围是有边界的,取决于所访问的物理地址空间。
各物理地址空间中可能的MECID值如下表所示。
| AxNSE | AxPROT[1] | 物理地址空间 | MECID |
|---|---|---|---|
| 0b0 | 0b0 | 安全(Secure) | 必须为0 |
| 0b0 | 0b1 | 非安全(Non-secure) | 必须为0 |
| 0b1 | 0b0 | 根(Root) | 必须为0 |
| 0b1 | 0b1 | 领域(Realm) | 任意值 |
对于以下请求操作码(Opcode),MECID不适用且可取任意值:
• CMO(缓存维护操作)
• CleanInvalid(清理并无效)
• MakeInvalid(置为无效)
• CleanShared(清理共享)
• CleanSharedPersist(持久化清理共享)
• InvalidateHint(无效化提示)
• StashTranslation(存储转换)
• UnstashTranslation(取出转换)
对于以下请求操作码,MECID不适用且必须为0:
• DVM Complete(分布式虚拟内存完成)
传播事务且在其从属设备(Subordinate)和主设备(Manager)接口上支持MECID的组件,必须在MECID适用的请求中保留该MECID。执行地址转换的组件可能会修改MECID。
存储带有关联MECID数据的缓存,必须同时存储该MECID,并在回写(write-back)时将其与数据一同提供。
CleanInvalidPoPA操作可用于确保加密点(Point of Encryption)上游的所有缓存中,某一缓存行被清理并无效化。有关CleanInvalidPoPA的更多信息,参见A10.9 缓存维护与领域管理扩展。
核心目的是通过MECID的精细化管理,确保不同地址空间的加密上下文正确匹配,同时兼容各类系统操作,平衡安全性与功能性。
6.7 多区域接口
本节描述如何将区域标识符与请求结合使用,以支持在单一接口中包含多个地址区域的场景。
6.7.1 区域标识符信号
REGION_Present属性决定接口是否支持区域标识符信号。
REGION_Present属性如下表所示。
| REGION_Present | 默认值 | 描述 |
|---|---|---|
| True | Y | 存在AWREGION和ARREGION信号。 |
| False | 不存在AWREGION和ARREGION信号。 |
用于指示区域的信号如下表所示。
| 名称 | 宽度 | 默认值 | 描述 |
|---|---|---|---|
| AWREGION、ARREGION | 4 | 0x0 | 4位区域标识符,可用于识别不同的地址区域。 |
6.7.2 区域标识符的使用
4位区域标识符最多可唯一识别16个不同区域。区域标识符可用于解码高阶地址位,且在任何4KB地址空间内必须保持不变。
使用区域标识符意味着,从属设备(Subordinate)上的单一物理接口可提供多个逻辑接口,每个逻辑接口在系统地址映射中处于不同位置。通过区域标识符,从属设备无需在不同逻辑接口之间进行地址解码。
本规范要求,当互连(interconnect)为具有多个逻辑接口的单一从属设备执行地址解码功能时,需生成AxREGION信号。若从属设备在系统地址映射中仅具有单一物理接口,互连必须使用AxREGION的默认值。
区域标识符的使用场景包括但不限于:
• 外设的主数据路径和控制寄存器可位于地址映射的不同位置,并通过单一接口访问,无需从属设备执行地址解码。
• 从属设备在不同内存区域可表现出不同行为(例如,某区域支持读写访问,另一区域仅支持只读访问)。
从属设备必须确保维持正确的协议信号和事务排序。对于具有相同事务ID但指向不同区域的两个请求,从属设备必须按正确顺序提供响应。
从属设备还必须确保对任何AxREGION值都能提供正确的协议信号。若从属设备实现的区域少于16个,则必须确保对任何访问不支持区域的尝试都能提供正确的协议信号。具体实现方式由实现定义(IMPLEMENTATION DEFINED),例如:
• 对访问不支持区域的任何事务提供错误响应。
• 将所有不支持的区域别名映射到支持的区域,确保所有访问都能得到符合协议的响应。
AxREGION信号仅用于对现有地址空间进行地址解码,方便从属设备省去地址解码功能,不创建新的独立地址空间。AxREGION仅允许出现在地址解码功能下游的接口上。
6.8 QoS信号
AXI通过以下特性支持服务质量(QoS)机制:
• QoS标识符
• QoS接受指示符
6.8.1 QoS标识符
AXI请求包含一个可选标识符,可用于区分不同的流量流,如下表所示。
QoS信号如下表所示。
| 名称 | 宽度 | 默认值 | 描述 |
|---|---|---|---|
| AWQOS、ARQOS | 4 | 0x0 | 用于区分不同流量流的服务质量标识符。 |
QOS_Present属性用于定义接口是否包含AxQOS信号。
QOS_Present属性如下表所示。
| QOS_Present | 默认值 | 描述 |
|---|---|---|
| True | Y | 存在AWQOS和ARQOS。 |
| False | 不存在AWQOS和ARQOS。 |
协议未指定QoS标识符的具体用途。建议将AxQOS用作关联写请求或读请求的优先级指示符,其中值越高表示请求优先级越高。
6.8.2 QoS标识符的使用
主设备(Manager)可生成自己的AxQOS值,若能生成多股流量流,可为不同流量流选择不同的QoS值。
支持QoS需要对所用QoS机制有系统级理解,且所有参与组件需协同工作。因此,建议主设备组件包含一定的可编程性,用于控制特定场景下使用的具体QoS值。
若主设备组件不支持可编程QoS机制,可使用代表其生成事务相对优先级的QoS值。必要时,这些值可映射为其他系统级QoS值。
本规范预期,许多互连(interconnect)组件实现会支持可编程寄存器,用于为连接的主设备分配QoS值。这些值会替换主设备提供的QoS值(无论是编程值还是默认值)。
QoS的默认系统级实现为:当组件有多个事务可供选择处理时,优先选择QoS值更高的请求进行处理。这种选择仅在没有其他AXI约束要求按特定顺序处理请求时发生。这意味着,AXI排序规则的优先级高于QoS排序。
6.8.2 QoS接受指示符
QoS_Accept信号是从属接口(Subordinate interface)的输出信号,用于指示其无延迟接受的最低QoS值。
这些信号与ACLK同步,但与其他AXI通道无关。
QoS_Accept信号如下表所示。
| 名称 | 宽度 | 默认值 | 描述 |
|---|---|---|---|
| VAWQOSACCEPT | 4 | 0x0 | 从属设备的输出,指示其接受AW通道请求的QoS值。 |
| VARQOSACCEPT | 4 | 0x0 | 从属设备的输出,指示其接受AR通道请求的QoS值。 |
QoS接受信号适用于为不同QoS值分配不同资源的从属组件(通常是内存控制器)。当低QoS值对应的资源被占用时,从属设备可通过该信号指示:仅接受特定QoS值及以上的请求。
QoS接受信号可作为管理器接口的输入——当管理器有多个请求可供选择时,仅发送可能被接受的请求,避免接口不必要的阻塞。通过防止发送可能被长时间阻塞的请求,接口可保留资源,以便后续处理可能到达的更高优先级请求。
在本规范中,术语VAxQOSACCEPT统称VAWQOSACCEPT和VARQOSACCEPT信号。
VAxQOSACCEPT信号的规则和建议如下:
• 任何QoS级别等于或高于VAxQOSACCEPT的请求,都会被从属设备接受。
• 任何QoS级别低于VAxQOSACCEPT的请求,可能被长时间阻塞。
本规范未定义从属设备必须接受“等于或高于指示QoS级别”请求的时间范围。但预期对于特定从属设备,在考虑时钟域交叉比等实现因素后,接受事务的最大时钟周期数是确定的。
• 从属接口允许接受QoS级别低于VAxQOSACCEPT指示值的请求,但此类请求可能面临显著延迟。
尽管从属设备可延迟优先级低于QoS接受级别的请求,但不建议无限延迟。
接口发送低优先级事务的原因包括但不限于:
• QoS接受值变化与组件适应变化之间存在延迟。
• 需要处理队头阻塞(Head-of-line blocking)高优先级请求的事务。
• 为防止饥饿(starvation),需要推进低优先级事务的处理。
QoS_Accept信号如下表所示。
| QoS_Accept | 默认值 | 描述 |
|---|---|---|
| True | 接口包含VAWQOSACCEPT和VARQOSACCEPT信号。 |
|
| False | Y | 接口不包含VAWQOSACCEPT和VARQOSACCEPT信号。 |
7 事务标识符与排序
本章描述了事务标识符,以及如何利用它们来控制事务的排序。
本章包含以下几个部分:
- 事务标识符
- 唯一 ID 指示符
- 请求排序
- 互连对事务标识符的使用
- 写数据与响应排序
- 读数据排序
7.1 事务标识符
AXI 协议包含一个事务标识符(AXI ID)。主设备(Manager)可以使用 AXI ID 来识别必须按顺序返回的事务。
所有具有相同 AXI ID 值的事务必须保持有序,但对于不同 ID 值的事务,其排序没有限制。单个物理端口可以通过充当多个逻辑端口来实现乱序(out-of-order)事务处理,每个逻辑端口都按顺序处理其事务。
通过使用 AXI ID,主设备可以在不等待早期事务完成的情况下发出新的事务。这可以提高系统性能,因为它能够实现事务的并行处理。
7.1.1 事务 ID 信号
读请求和写请求、读数据以及写响应通道都包含一个事务 ID 信号。
| 名称 | 宽度 | 默认值 | 描述 |
|---|---|---|---|
| AWID, BID | ID_W_WIDTH |
All zeros |
用于写请求和响应排序的事务标识符。 |
| ARID, RID | ID_R_WIDTH |
All zeros |
用于读请求、响应和数据排序的事务标识符。 |
ID_W_WIDTH 和 ID_R_WIDTH 属性如下表所示。
| 名称 | 值 | 默认值 | 描述 |
|---|---|---|---|
ID_W_WIDTH |
0..32 | - | 写通道上的 ID 宽度,以比特为单位,适用于 AWID 和 BID。 |
ID_R_WIDTH |
0..32 | - | 读通道上的 ID 宽度,以比特为单位,适用于 ARID 和 RID。 |
如果宽度属性为零,则关联的信号不存在。
不支持其请求和响应重新排序,或者只有一个未完成事务的主设备,可以从其接口中省略 ID 信号。连接的从属设备(Subordinate)必须将其 AxID 输入绑定到 LOW。
不重新排序请求或响应的从属设备不需要使用 ID 值。
如果一个从属设备不包含 ID 信号,它就不能连接到具有 ID 信号的主设备,因为主设备要求 BID 和 RID 必须从 AWID 和 ARID 反射(reflected)回来。
7.2 唯一 ID 指示符
唯一 ID 指示符是一个可选标志,用于指示读或写地址通道上的请求是否正在使用一个对正在传输中的事务而言是唯一的 AXI ID。读和写响应通道上也有一个相应的信号来指示某个事务正在使用一个唯一的 ID。
唯一 ID 指示符可以在 AXI 主设备(Manager)的下游组件中使用,以确定某个请求是否需要与来自该主设备的其他请求进行排序。不需要排序的请求可能不需要在下游组件中进行追踪。
Unique_ID_Support 属性用于指示接口是否支持唯一 ID 指示。
Unique_ID_Support |
默认值 | 描述 |
|---|---|---|
True |
- | 接口上存在唯一 ID 指示符信号。 |
False |
Y | 接口上不存在唯一 ID 指示符信号。 |
当 Unique_ID_Support 为 True 时,读请求、读数据、写请求和写响应通道上会包含以下信号。
| 名称 | 宽度 | 默认值 | 描述 |
|---|---|---|---|
AWIDUNQ、BIDUNQ、ARIDUNQ、RIDUNQ |
1 | 0b0 |
如果置高(asserted high),表示此传输的 ID 在“正在传输中”(in-flight)是唯一的。 |
以下规则适用于唯一 ID 指示符:
- 当
AWIDUNQ置高时,来自该主设备的、使用相同AWID值的**未完成(outstanding)**写事务必须不存在。 - 主设备不能发出一个与之前已置高
AWIDUNQ的未完成写事务具有相同AWID的写请求。 - 如果一个请求的
AWIDUNQ被置低,则在单次传输响应或多次传输响应的“完成”(Completion)部分,其对应的BIDUNQ信号也必须被置低。 - 如果一个请求的
AWIDUNQ被置高,则在单次传输响应或多次传输响应的“完成”(Completion)部分,其对应的BIDUNQ信号也必须被置高。 - 当
ARIDUNQ置高时,来自该主设备的、使用相同ARID值的未完成读事务必须不存在。 - 主设备不能发出一个与之前已置高
ARIDUNQ的未完成读事务具有相同ARID的读请求。 - 如果一个请求的
ARIDUNQ被置低,则对于该事务的所有响应传输,其对应的RIDUNQ信号也必须被置低。 - 如果一个请求的
ARIDUNQ被置高,则对于该事务的所有响应传输,其对应的RIDUNQ信号也必须被置高。 - 对于包含读和写响应的原子(Atomic)事务,适用附加规则:
- 如果一个原子请求的
AWIDUNQ被置低,则对于该事务的所有响应传输,其对应的RIDUNQ信号也必须被置低。 - 如果一个原子请求的
AWIDUNQ被置高,则对于该事务的所有响应传输,其对应的RIDUNQ信号也必须被置高。
- 如果一个原子请求的
一个事务从 AxVALID 置高的周期开始,直到主设备接受最终响应传输的周期为止,都被认为是未完成(outstanding)。如果接口包含 BCOMP,则事务被视为未完成,直到接收到 BCOMP 置高的响应。
一个原子事务直到主设备同时接受写和读响应后才被视为完成。
一些事务类型要求,如果存在 AxIDUNQ,则它必须被置高。如果没有指定,即使没有使用相同 ID 的未完成事务,置高 AxIDUNQ 也是可选的。
7.3 请求排序
AXI 请求排序模型基于事务标识符的使用,该标识符在 ARID 或 AWID 上进行信号传输。
在同一通道上,具有相同 ID 和相同目的地的事务请求,保证按顺序保持。具有相同 ID 的事务响应,按照请求发出的相同顺序返回。
排序模型不提供以下事务之间的排序保证:
- 来自不同主设备的事务
- 读事务和写事务
- 具有不同 ID 的事务
- 发往不同外设区域(Peripheral regions)的事务
- 发往不同内存位置(Memory locations)的事务
如果主设备需要对没有排序保证的事务进行排序,则主设备必须等待接收到第一个事务的响应后,才能发出第二个事务。
7.3.1 内存位置和外设区域
AMBA 中的地址映射由内存位置(Memory locations)和外设区域(Peripheral regions)组成。
一个内存位置具有以下所有属性:
- 从内存位置读取一个字节,会返回最后写入该字节位置的值。
- 对内存位置的字节进行写入,会将该位置的值更新为一个新值,该新值可以通过后续对该位置的读取来获得。
- 对内存位置的读或写,对任何其他内存位置都没有副作用(side-effects)。
- 内存的观察保证(Observation guarantees)是针对每个位置给出的。
- 内存位置的大小等于该组件的单拷贝原子性(single-copy atomicity)大小。
一个外设区域具有以下所有属性:
- 从外设区域的某个地址读取,不一定返回最后写入该地址的值。
- 对外设区域的某个字节地址进行写入,不一定将该地址的值更新为一个新值,该新值可以通过后续读取来获得。
- 访问外设区域内的某个地址,可能对该区域内的其他地址产生副作用。
- 外设的观察保证是针对每个区域给出的。
- 外设区域的大小是由实现定义的(IMPLEMENTATION DEFINED),但它必须包含在一个单一的从属组件内。
一个事务可以涉及一个或多个地址位置。这些位置由 AxADDR 和任何相关限定符(如地址空间)确定。
- 排序保证只在对相同的内存位置或外设区域的访问之间提供。
- 发往外设区域的事务必须完全包含在该区域内。
- 跨越多个内存位置的事务具有多重排序保证。
7.3.2 设备(Device)与普通(Normal)请求
事务可以是设备(Device)类型或普通(Normal)类型。
设备(Device)
- 当请求的
AxCACHE[1]信号为低(deasserted)时,读或写操作即为设备类型。 - 设备事务可用于访问外设区域或内存位置。
普通(Normal)
- 当请求的
AxCACHE[1]信号为高(asserted)时,读或写操作即为普通类型。 - 普通事务用于访问内存位置,通常不用于访问外设区域。
- 对外设区域的普通类型访问,必须以符合协议的方式完成,但其结果是由实现定义的(IMPLEMENTATION DEFINED)。
7.3.3 观察(Observation)与完成(Completion)定义
对于对外设区域的访问,当设备读或写访问 DRW1 在 DRW2 之前到达从属组件时,则认为 DRW1 被设备读或写访问 DRW2 所观察。
对于对内存位置的访问,以下所有情况都适用:
- 如果写入
W2在W1之后生效,则W1被写入W2所观察。 - 如果读取
R1返回来自写入W3的数据,且W2在W3之后,则读取R1被写入W2所观察。 - 如果读取
R2返回来自写入W1或写入W3的数据,且W3在W1之后,则写入W1被读取R2所观察。
读取 R1 或写入 W1 可以是设备(Device)或普通(Normal)类型。
写入和读取的完成(completion)定义如下:
写入完成响应
当BVALID、BREADY和BCOMP(如果存在) 都置高时,与之关联的BRESP握手发生时的周期。读取完成响应
当RVALID、RLAST和RREADY都置高时,与之关联的最后一个RDATA握手发生时的周期。
7.3.4 主设备排序保证
有三种类型的排序模型保证:
- 在接收到完成响应之前的**可观察性(Observability)**保证。
- 基于完成响应的可观察性保证。
- 响应排序保证。
在接收到完成响应之前的可观察性保证
以下所有保证适用于来自同一主设备且使用相同 ID 的事务:
- 设备写入
DW1保证在设备写入DW2之前到达目的地,其中DW2是在DW1之后发出的,且两者都发往相同的外设区域。 - 设备读取
DR1保证在设备读取DR2之前到达目的地,其中DR2是在DR1之后发出的,且两者都发往相同的外设区域。 - 写入
W1保证被写入W2所观察,其中W2是在W1之后发出的,且两者都发往相同的内存位置。 - 被读取
R2所观察到的写入W1,保证被读取R3所观察,其中R3是在R2之后发出的,且两者都发往相同的内存位置。
基于完成响应的可观察性保证
基于完成响应的保证如下:
- 对于一个读请求,其完成响应保证对来自任何主设备的后续读或写请求是可观察的。
- 对于一个不可缓冲(Non-bufferable)的写请求,其完成响应保证对来自任何主设备的后续读或写请求是可观察的。
- 对于一个可缓冲(Bufferable)的写请求,其完成响应可以从中间点发送。它不保证写入已在终点完成,但根据请求的域(Domain)提供可观察性保证:
- 不可共享(Non-shareable):仅对发出请求的主设备可观察。
- 可共享(Shareable):对可共享域中的所有其他主设备可观察。
- 系统(System):对所有其他主设备可观察。
响应排序保证
事务响应具有以下所有排序保证:
- 如果读取
R2是在读取R1之后从同一主设备发出且具有相同ID,则读取R1保证在读取R2之前收到响应。 - 如果写入
W2是在写入W1之后从同一主设备发出且具有相同ID,则写入W1保证在写入W2之前收到响应。
7.3.5 从属设备(Subordinate)排序要求
为了满足主设备(Manager)的排序保证,从属设备接口必须满足以下要求。
外设位置(Peripheral locations)
对于外设位置,事务的执行顺序是由实现定义的(IMPLEMENTATION DEFINED)。这个执行顺序通常预期与到达顺序一致,但这并非强制要求。
内存位置(Memory locations)
- 一个写入
W1必须在写入W2之前排序,其中W2是在W1之后接收到的,且两者具有相同的 ID 并指向相同的内存位置。 - 一个写入
W1必须在写入W2之前排序,其中W2是在W1的完成响应给出之后接收到的,且两者指向相同的内存位置。 - 一个写入
W1必须在读取R2之前排序,其中R2是在W1的完成响应给出之后接收到的,且两者指向相同的内存位置。 - 一个读取
R1必须在写入W2之前排序,其中W2是在R1的完成响应给出之后接收到的,且两者指向相同的内存位置。
响应排序要求
- 读取
R1的响应必须在读取R2的响应之前返回,其中R2是在R1之后接收到的,且两者具有相同的 ID。 - 写入
W1的响应必须在写入W2的响应之前返回,其中W2是在W1之后接收到的,且两者具有相同的 ID。
7.3.6 互连(Interconnect)排序要求
一个互连组件具有以下属性:
- 请求在一个端口接收,然后要么在另一个端口发出,要么被响应。
- 响应在一个端口接收,然后要么在另一个端口发出,要么被消费(consumed)。
当互连发出请求或响应时,它必须遵守以下要求:
- 读取
R1请求必须在读取R2请求之前发出,其中R2是在R1之后接收到的,且具有相同的 ID 并指向相同或重叠的位置。 - 写入
W1请求必须在写入W2请求之前发出,其中W2是在W1之后接收到的,且具有相同的 ID 并指向相同或重叠的位置。 - 设备读
DR1请求必须在设备读DR2请求之前发出,其中DR2是在DR1之后接收到的,且具有相同的 ID 并指向相同的外设区域。 - 设备写
DW1请求必须在设备写DW2请求之前发出,其中DW2是在DW1之后接收到的,且具有相同的 ID 并指向相同的外设区域。 - 读取
R1响应必须在读取R2响应之前发出,其中R2是在R1之后接收到的,且具有相同的 ID。 - 写入
W1响应必须在写入W2响应之前发出,其中W2是在W1之后接收到的,且具有相同的 ID。
当互连充当从属组件时,它也必须遵守从属组件的要求。
任何对与事务相关联的 AXI ID 值进行的修改,都必须确保原始 ID 值的排序要求得到维护。
7.3.7 终点之前的响应
为了提高系统性能,中间组件可以对某些事务发出响应。这种行为被称为早期响应(early response)。发出早期响应的中间组件必须确保**可见性(visibility)和排序(ordering)**保证得到满足。
早期读响应
对于普通(Normal)的读事务,如果中间组件的本地内存与所有早先对相同或重叠地址的写入保持最新(up to date),它可以从本地内存返回读数据。在这种情况下,请求不需要再向下游传播。
一个中间组件必须遵守 ID 排序规则,这意味着只有当所有具有相同 ID 的早期读事务都已获得响应时,才能发送读响应。
早期写响应
对于可缓冲(Bufferable)的写事务(AWCACHE[0] 置高),如果事务没有下游观察者,中间组件可以发送一个早期写响应。如果中间组件发送了早期写响应,它可以存储数据的本地副本,但在丢弃该数据之前,必须将该事务向下游传播。
一个中间组件必须遵守 ID 排序规则,这意味着只有当所有具有相同 ID 的早期写事务都已获得响应时,才能发送写响应。
在发送早期写响应之后,该组件必须负责该事务的排序和可见性,直到写入已向下游传播并接收到写响应为止。在发送早期写响应和从下游接收响应之间的这段时间内,该组件必须确保:
- 如果为普通(Normal)事务发出了早期写响应,那么所有后续对相同或重叠内存位置的事务,都必须在该早期响应的写入之后进行排序。
- 如果为设备(Device)事务发出了早期写响应,那么所有后续对相同外设区域的事务,都必须在该早期响应的写入之后进行排序。
当为一个设备可缓冲(Device Bufferable)事务给出早期写响应时,中间组件应在不依赖于其他事务的情况下传播该写事务。中间组件不能等待另一个读或写到达,然后才传播之前的设备写事务。
7.3.8 不同内存类型请求之间的排序
可缓存(Cacheable)请求与设备(Device)或不可缓存(Non-cacheable)的普通(Normal)请求之间没有排序要求。
设备请求与普通不可缓存请求之间的排序要求,取决于 Device_Normal_Independence 属性。
Device_Normal_Independence |
默认值 | 描述 |
|---|---|---|
| True | 允许一个设备请求超越,或被一个具有相同 ID 且访问相同位置的普通不可缓存请求超越。 | |
| False | Y | 具有相同 ID 且访问相同位置的设备和普通不可缓存请求,必须按发出顺序进行观察。 |
关于如何连接具有不同 Device_Normal_Independence 值的主设备和从属设备接口的指导,如下表所示。
| 从属设备:False | 从属设备:True | |
|---|---|---|
| 主设备:False | 兼容。 | 不兼容。 从属设备可能无法满足主设备的排序要求。 |
| 主设备:True | 兼容。 从属设备可能会执行比要求更严格的排序。 | 兼容。 |
7.3.9 有序写观察(Ordered Write Observation)
为了提高与支持不同排序模型的接口协议的兼容性,从属设备接口可以为写事务提供更强的排序保证,这被称为有序写观察。
Ordered_Write_Observation 属性用于定义一个接口是否具有有序写观察。
Ordered_Write_Observation |
默认值 | 描述 |
|---|---|---|
| True | 接口表现出有序写观察。 | |
| False | Y | 接口不表现出有序写观察。 |
一个表现出有序写观察的接口,为写事务提供了不依赖于目的地或地址的保证:
- 一个写入
W1保证被写入W2所观察,其中W2是在W1之后从同一主设备发出,且具有相同 ID。
当使用有序写观察时,主设备可以发出多个写请求,而无需等待写响应,并且它们会按发出顺序被观察到。这在使用**生产者-消费者(Producer-Consumer)**排序模型时,可以带来性能提升。
7.4 互连对事务标识符的使用
当一个主设备(Manager)连接到互连(interconnect)时,互连会向 AWID 和 ARID 标识符追加额外比特,以使该主设备端口的标识符变得唯一。这会产生两个效果:
- 主设备不需要知道其他主设备使用的 ID 值。因为互连通过在原始标识符后追加主设备编号,使得每个主设备使用的 ID 值都变得唯一。
- 在从属设备(Subordinate)接口上的 ID 标识符,会比在主设备接口上的更宽。
对于写响应,互连会使用 BID 标识符中的额外比特来确定写响应应该发往哪个主设备端口。互连会在将 BID 值传递给正确的主设备端口之前,移除这些额外比特。
对于读数据,互连会使用 RID 标识符中的额外比特来确定读数据应该发往哪个主设备端口。互连会在将 RID 值传递给正确的主设备端口之前,移除这些额外比特。
7.5 写数据与响应排序
从属设备必须确保写响应的 BID 值与它所响应的请求的 AWID 值相匹配。
主设备必须按照发出事务请求的相同顺序来发出写数据。
一个组合来自不同主设备的写事务的互连(interconnect),必须确保它以请求的顺序转发写数据。不允许不同事务的写数据传输进行交错。
互连必须确保,来自一系列具有相同 AWID 值但目标是不同从属设备的事务的写响应,能够以请求的顺序被主设备接收。
7.6 读数据排序
从属设备必须确保任何返回数据的 RID 值与其所响应的请求的 ARID 值相匹配。
互连必须确保,来自一系列具有相同 ARID 值但目标是不同从属设备的事务的读数据,能够以请求的顺序被主设备接收。
读数据重排序深度是从属设备可能发送读数据的最大已接受请求数。一个以与请求接收顺序相同的顺序发送读数据的从属设备,其读数据重排序深度为 1。
读数据重排序深度是一个静态值,可以由从属设备的设计者指定。
没有机制可以让主设备动态地确定从属设备的读数据重排序深度。
7.6.1 读数据交错
AXI 排序允许具有不同 ID 值的读数据传输进行交错(interleaved)。这适用于所有可以有多个读数据传输的事务,包括原子(Atomic)事务。
如果能在设计时确定所连接的从属设备接口是否会交错来自不同事务的读数据,那么一些 AXI 主设备和互连组件可以被设计得更高效。
Read_Interleaving_Disabled 属性用于指示一个接口是否支持来自不同事务的读数据传输交错。
Read_Interleaving_Disabled |
默认值 | 描述 |
|---|---|---|
| True | 主设备接口无法接收交错的读数据。从属设备接口保证不交错读数据。 | |
| False | Y | 主设备接口能够接收交错的读数据。从属设备接口可能交错来自不同 ARID 值的读数据。 |
对于某些接口,此属性可以作为配置控制使用,而对于其他接口,它是一个能力指示符。所有发出不同 ID 事务的主设备都必须被设计成能接受交错的数据。当所连接的从属设备支持禁用交错时,主设备可以使用该配置选项作为优化手段来禁用交错。
7.6.2 读数据分块
读数据分块选项允许从属设备接口以 128b 粒度对事务内的读数据进行重排序。起始地址可以作为提示来决定首先发送哪个分块,但从属设备被允许以任何顺序返回数据分块。
Read_Data_Chunking 属性用于指示一个接口是否支持返回可重排序的数据分块。
Read_Data_Chunking |
默认值 | 描述 |
|---|---|---|
True |
支持读数据分块。 | |
False |
Y | 不支持读数据分块,没有分块信号。 |
7.6.2.1 读数据分块信号
当支持读数据分块时,如下表所示的信号会被添加到读请求和数据通道。
| 名称 | 宽度 | 默认值 | 描述 |
|---|---|---|---|
ARCHUNKEN |
1 | 0b0 |
如果在读请求中置高,则从属设备可以以 128b 分块发送读数据。 |
RCHUNKV |
1 | 0b0 |
置高以指示 RCHUNKNUM 和 RCHUNKSTRB 有效。在事务的每次响应中都必须相同。 |
RCHUNKNUM |
RCHUNKNUM_WIDTH |
All zeros |
指示正在传输的分块编号。分块根据数据宽度和事务基地址从零开始递增编号。 |
RCHUNKSTRB |
RCHUNKSTRB_WIDTH |
All ones |
指示此传输中有效的读数据分块。每个位对应 128 位数据。RCHUNKSTRB 的最低有效位对应 RDATA 的最低有效 128 位。 |
RCHUNKNUM_WIDTH 属性定义了 RCHUNKNUM 信号的宽度。
| 名称 | 值 | 默认值 | 描述 |
|---|---|---|---|
RCHUNKNUM_WIDTH |
0, 1, 5, 6, 7, 8 | 0 | RCHUNKNUM 的宽度,以比特为单位。如果 Read_Data_Chunking == False 则必须为 0。如果 DATA_WIDTH < 128 则为 0 或 1。如果 DATA_WIDTH == 128 则为 8。如果 DATA_WIDTH == 256 则为 7。如果 DATA_WIDTH == 512 则为 6。如果 DATA_WIDTH == 1024 则为 5。 |
RCHUNKSTRB_WIDTH 属性定义了 RCHUNKSTRB 信号的宽度。
| 名称 | 值 | 默认值 | 描述 |
|---|---|---|---|
RCHUNKSTRB_WIDTH |
0, 1, 2, 4, 8 | 0 | RCHUNKSTRB 的宽度,以比特为单位。如果 Read_Data_Chunking == False 则必须为 0。如果 DATA_WIDTH < 256 则为 0 或 1。如果 DATA_WIDTH == 256 则为 2。如果 DATA_WIDTH == 512 则为 4。如果 DATA_WIDTH == 1024 则为 8。 |
DATA_WIDTH 较小的接口可以包含 1 比特宽的 RCHUNKNUM 和 RCHUNKSTRB 信号,或从接口中省略它们。当使用接口保护时,RCHUNKCHK 信号覆盖这两个信号,因此对于连接的组件,RCHUNKNUM 和 RCHUNKSTRB 必须是相同的宽度。
建议如果接口不需要 RCHUNKNUM 和 RCHUNKSTRB,则省略它们。
7.6.2.2 读数据分块协议规则
在读数据分块协议中,以下所有规则都适用:
ARCHUNKEN必须仅在满足以下条件的事务中置高:- **大小(Size)等于数据通道的宽度,或长度(Length)**为一次传输。
- 大小为 128 位或更大。
- **地址(Addr)**对齐到 16 字节。
- **突发(Burst)**类型为
INCR或WRAP。 - **操作码(Opcode)**为
ReadNoSnoop、ReadOnce、ReadOnceCleanInvalid或ReadOnceMakeInvalid。
ID值必须是正在传输中唯一的(unique-in-flight),这意味着:- 只有当没有使用相同
ARID值的未完成读事务时,ARCHUNKEN才能被置高。 - 主设备不能发出一个与已置高
ARCHUNKEN的未完成请求具有相同ARID的请求。 - 如果接口上存在
ARIDUNQ,那么当ARCHUNKEN被置高时,ARIDUNQ也必须被置高。
- 只有当没有使用相同
- 如果
ARCHUNKEN被置低,则事务的所有响应传输的RCHUNKV必须被置低。 - 如果
ARCHUNKEN被置高,则事务的响应传输的RCHUNKV可以被置高。 RCHUNKV在一个事务的每次响应传输中必须是相同的。- 当
RVALID和RCHUNKV被置高时,RCHUNKNUM必须在 0 和ARLEN之间。 - 当
RVALID和RCHUNKV被置高时,RCHUNKSTRB不得为零。 - 当
RVALID和RCHUNKV被置高时,RLAST必须仅在事务的最终响应传输中被置高,而与RCHUNKNUM和RCHUNKSTRB无关。 - 当
RVALID被置高且RCHUNKV被置低时,RCHUNKNUM和RCHUNKSTRB可以取任何值。
传输的数据分块数量必须与 ARLEN 和 ARSIZE 保持一致,因此无论是否启用分块,事务中传输的字节数是相同的。请注意,当使用读数据分块时,一个事务的读数据传输次数可能比 ARLEN 所指示的要多。
对于未对齐的事务,地址低于 ARADDR 的分块不会被传输,并且必须将 RCHUNKSTRB 置低。
7.6.2.3 互操作性
如果一个主设备(Manager)支持读数据分块,那么下游的互连(interconnect)和从属设备(Subordinate)如果也支持分块,就可以减少它们的缓冲。一个连接到支持分块能力不同的组件的互连,可以根据所连接组件的能力来驱动 ARCHUNKEN 和 RCHUNKV。
当连接 Read_Data_Chunking 属性值不同的接口时,以下规则适用,如下表所示。
从属设备:False |
从属设备:True |
|
|---|---|---|
主设备:False |
ARCHUNKEN 不存在。RCHUNKV 不存在。RCHUNKNUM 不存在。RCHUNKSTRB 不存在。发送完整数据传输且顺序自然。 |
从属设备的 ARCHUNKEN 输入被tied为低。从属设备的 RCHUNKV 输出未连接。从属设备的 RCHUNKNUM 输出未连接。从属设备的 RCHUNKSTRB 输出未连接。发送完整数据传输且顺序自然。 |
主设备:True |
主设备的 ARCHUNKEN 输出未连接。主设备的 RCHUNKV 输入被tied为低。主设备的 RCHUNKNUM 输入被tied。主设备的 RCHUNKSTRB 输入被tied。发送完整数据传输且顺序自然。 |
分块信号已连接。 读数据可以被重排序并以分块形式发送。 |
7.6.2.4 分块示例
在这些示例中,图中的每一行代表一次传输,阴影单元格表示未传输的字节。
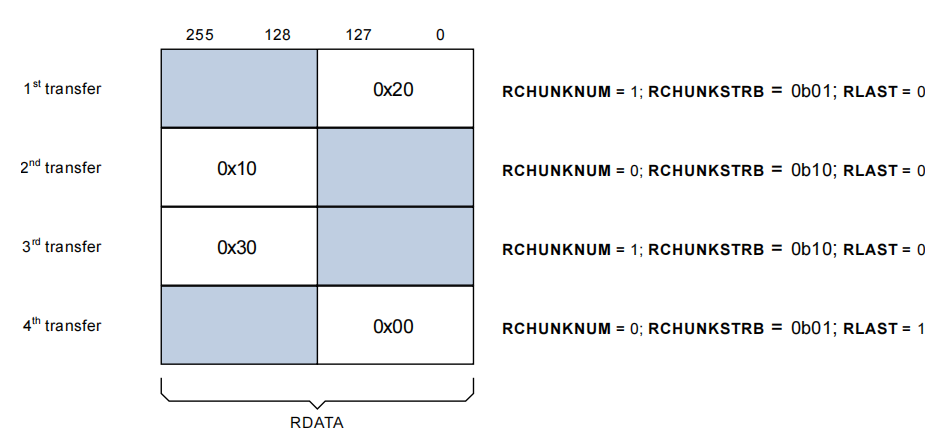
下图展示了一个 256 位宽的读数据通道上的事务,其中:
- 地址(Addr) 是
0x00。 - 长度(Length) 是 2 次传输。
- 大小(Size) 是 256 位。
- 突发(Burst) 类型是
INCR。
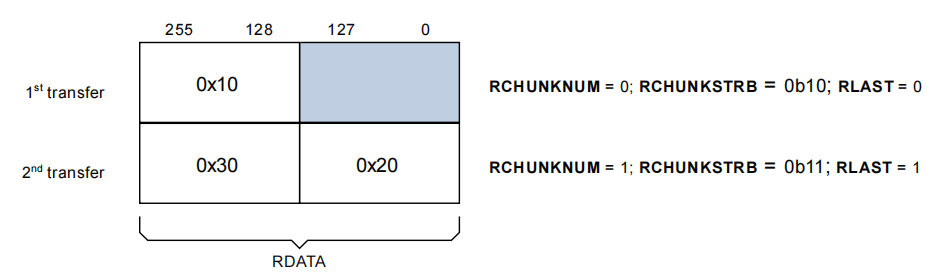
下图展示了一个 256 位宽的读数据通道上的事务,其中:
- 地址(Addr) 是
0x10。 - 长度(Length) 是 2 次传输。
- 大小(Size) 是 256 位。
- 突发(Burst) 类型是
INCR。
下图展示了一个 128 位宽的读数据通道上的事务,其中:
- 地址(Addr) 是
0x10。 - 长度(Length) 是 4 次传输。
- 大小(Size) 是 128 位。
- 突发(Burst) 类型是
WRAP。 RCHUNKSTRB不存在。- 从属设备使用起始地址作为提示,并首先发送位于
0x10的分块。
![]()
8 原子访问
原子访问
本章描述了单拷贝原子性(single-copy atomicity)和多拷贝原子性(multi-copy atomicity),以及如何执行独占访问(exclusive accesses)和原子事务(atomic transactions)。
本章包含以下几个部分:
- 单拷贝原子性大小
- 多拷贝写入原子性
- 独占访问
- 原子事务
8.1 单拷贝原子性大小
单拷贝原子性大小是事务以原子方式更新的最小字节数。AXI 协议要求,大于单拷贝原子性大小的事务,必须以至少为单拷贝原子性大小的块来更新内存。
原子性并不定义数据更新的确切瞬间。必须确保的是,没有任何主设备能够观察到原子数据被部分更新的形式。例如,在许多系统中,诸如链表之类的数据结构是由 32 位原子元素组成的。对其中一个元素的原子更新要求整个 32 位值在同一时间被更新。任何主设备观察到一次只更新 16 位,然后稍后更新另外 16 位,这是不可接受的。
更复杂的系统需要支持更大的原子元素,特别是 64 位原子元素,以便主设备可以使用基于这些更大原子元素的数据结构进行通信。
系统中支持的单拷贝原子性大小非常重要,因为给定通信中涉及的所有组件都必须支持所需的原子元素大小。如果两个主设备通过一个互连和一个从属设备进行通信,那么所有涉及的组件都必须确保所需大小的事务被原子地处理。
AXI 协议不要求特定的单拷贝原子性大小,系统可以被设计为支持不同的单拷贝原子性大小。
在 AXI 中,术语单拷贝原子组(single-copy atomic group)描述了一组能够以特定原子性进行通信的组件。例如,下图展示了一个系统,其中:
- CPU、DSP、DRAM 控制器、DMA 控制器、外设、SRAM 内存及其关联的互连,都处于一个 32 位单拷贝原子组中。
- CPU、DSP、DRAM 控制器及其关联的互连,也处于一个 64 位单拷贝原子组中。
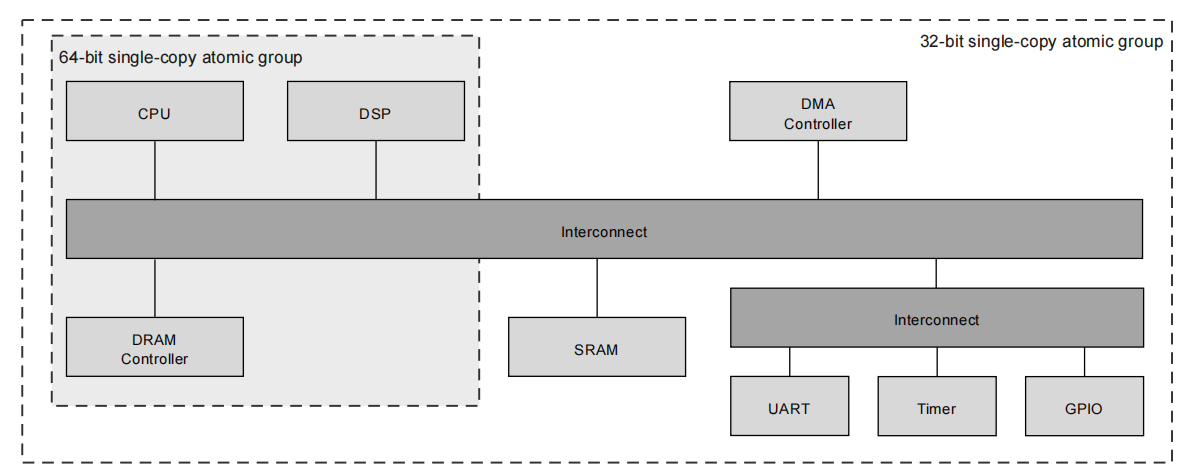
事务的原子性保证永远不会大于其起始地址的对齐。例如,在一个 64 位单拷贝原子组中的事务,如果其地址没有对齐到 8 字节边界,则它不具有任何 64 位单拷贝原子性保证。
与事务相关的字节选通(byte strobes)不影响单拷贝原子性大小。
8.2 多拷贝写入原子性
一个系统如果满足以下条件,则被定义为具有多拷贝原子性(multi-copy atomic):
- 所有从设备(agent)都以相同的顺序观察到对同一位置的写入。
- 一个从设备如果能观察到对某个位置的写入,那么所有从设备都能观察到该写入。
为了指定一个系统提供多拷贝原子性,定义了一个 Multi_Copy_Atomicity 属性。
Multi_Copy_Atomicity |
默认值 | 描述 |
|---|---|---|
True |
支持多拷贝原子性。 | |
False |
Y | 不支持多拷贝原子性。 |
多拷贝原子性可以通过以下方式确保:
- 对给定地址使用单一序列化点(Point of Serialization, PoS),从而使所有对同一位置的访问都得到排序。这必须确保在位置的新值对任何从设备可见之前,该位置的所有相干缓存拷贝(coherent cached copies)都被置为无效(invalidated)。
- 避免使用位于任何从设备上游的转发缓冲区(forwarding buffers)。这可以防止某个位置的缓冲写入在对所有从设备可见之前,就已经对部分从设备可见。
对于本规范的 G 版及以后的版本,要求 Multi_Copy_Atomicity 属性为 True。
8.3 独占访问
独占访问(exclusive access)机制可以提供类似**信号量(semaphore)**的操作,而不需要在操作期间保持与特定主设备的专用连接。
AxLOCK 信号用于指示独占访问,而 BRESP 和 RRESP 信号则分别指示独占写或读的成功或失败。
| 名称 | 宽度 | 默认值 | 描述 |
|---|---|---|---|
AWLOCK, ARLOCK |
1 | 0b0 |
置高以指示需要独占访问。 |
Exclusive_Accesses 属性用于定义主设备是否发出独占访问,或者从属设备是否支持独占访问:
Exclusive_Accesses |
默认值 | 描述 |
|---|---|---|
True |
Y | 支持独占访问。接口上存在 AWLOCK 和 ARLOCK 信号。 |
False |
不支持独占访问。接口上不存在 AWLOCK 和 ARLOCK 信号。 |
下表提供了连接具有不同属性值的主设备和从属设备组件时的指导:
从属设备:False |
从属设备:True |
|
|---|---|---|
主设备:False |
兼容。 | 兼容。AWLOCK 和 ARLOCK 被tied为低。 |
主设备:True |
不兼容。独占访问会持续失败,但接口不会死锁。 | 兼容。 |
8.3.1 独占访问序列
独占访问序列的机制是:
- 主设备从一个地址发出独占读请求。
- 稍后,主设备通过向相同地址发出独占写请求来尝试完成独占操作,其
AWID与独占读使用的ARID相匹配。 - 此独占写访问被标记为:
- 成功,如果自独占读访问以来没有其他主设备写入该位置。在这种情况下,独占写会更新内存。
- 失败,如果自独占读访问以来有其他主设备写入该位置。在这种情况下,内存位置不被更新。
主设备可能不会完成独占操作的写部分。独占访问监控硬件为每个事务 ID 仅监控一个地址。如果主设备没有完成独占操作的写部分,那么该主设备随后使用相同事务 ID 的独占读会改变被监控的独占访问地址。
8.3.2 从主设备的角度看独占访问
主设备通过执行独占读来启动独占操作。如果事务成功,从属设备会返回 EXOKAY 响应,表明从属设备记录了该地址以进行独占访问监控。
如果主设备尝试从一个不支持独占访问的从属设备进行独占读,从属设备会返回 OKAY 响应而不是 EXOKAY。在这种情况下,读数据是有效的,但该位置未被监控以确保独占性。
主设备可以将 OKAY 响应视为指示独占访问不被支持的错误条件。建议主设备在这种情况下不要执行此独占操作的写部分。
在独占读之后的一段时间,主设备会尝试对相同位置进行独占写。如果自独占读以来,该地址位置的内容没有被更新,则独占写操作成功。从属设备返回 EXOKAY 响应,并更新内存位置。
如果自独占读以来,该地址位置的内容已被更新,则独占写尝试失败,从属设备返回 OKAY 响应而不是 EXOKAY。独占写尝试不更新内存位置。
主设备可能不会完成独占操作的写部分。如果发生这种情况,从属设备会继续监控该地址以进行独占访问,直到另一个独占读启动一个新的独占访问序列。
主设备必须在独占读部分完成之后,才能启动独占访问序列的写部分。
8.3.3 独占访问限制
以下限制适用于独占访问:
- 独占访问的地址必须对齐到事务中的总字节数,即
Size和Length的乘积。 - 独占访问事务中要传输的字节数必须是2 的幂,即 1、2、4、8、16、32、64 或 128 字节。
- 独占事务中可传输的最大字节数为 128 字节。
- 独占访问的
Length不得超过 16 次传输。 - **域(Domain)**不得为
Shareable,参见 A9.3.3 可共享域。 - **操作码(Opcode)**必须是
ReadNoSnoop或WriteNoSnoop。参见 A8 章 请求操作码。 AWTAGOP不得为Match,参见 A13.2 内存标签扩展(MTE)。
不遵守这些限制会导致不可预测的行为(UNPREDICTABLE behavior)。
为了使独占序列成功,AxCACHE 的值必须是适当的,以确保读和写请求能到达独占访问监控器。
在独占操作期间,需要监控的最小字节数是 Size 和 Length 的乘积。从属设备可以监控多达 128 字节,这是独占访问中最大的字节数。然而,这可能导致一个本应成功的独占访问被指示为失败,因为一个相邻的字节被更新了。
如果独占序列中读请求和写请求之间的下表中显示的任何信号不同,即使该位置没有被其他代理更新,独占写也可能失败。
AxID |
AxADDR |
AxREGION |
AxSUBSYSID |
AxDOMAIN |
|---|---|---|---|---|
AxLEN |
AxSIZE |
AxBURST |
AxLOCK |
AxCACHE[1:0] |
AxPROT |
AxNSE |
AxSNOOP |
AxMMUATST |
AxMMUFLOW |
AxMMUVALID |
AxMMUSECSID |
AxMMUSID |
AxMMUSSID |
AxMMUSSIDV |
8.3.4 从属设备(Subordinate)角度看独占访问
支持独占访问的从属设备必须具有监控硬件(monitor hardware)。建议此类从属设备为每个能够访问它的、支持独占访问的主设备 ID 设置一个监控单元。
当从属设备收到一个独占读请求时,它会记录独占读操作的地址和 ARID 值。然后,它会监控该位置,直到该位置发生写入,或者直到另一个使用相同 ARID 值的独占读将监控器重置到另一个地址。
如果从属设备可以成功处理独占读,它会为每一次读数据传输返回 EXOKAY 响应。
如果从属设备无法处理独占读,它会返回一个不是 EXOKAY 的响应。一个独占读可以有多个响应传输。对于单个事务,不允许混合使用 OKAY 和 EXOKAY 响应。
当从属设备收到一个具有给定 AWID 值的独占写时,监控器会检查是否正在使用该 AWID 监控该地址。如果是,则表明自独占读访问以来没有写入该位置,独占写将继续进行,完成独占访问。从属设备向主设备返回 EXOKAY 响应,并更新被寻址的内存位置。
如果在独占写时,该地址没有以相同的 AWID 值被监控,这表明以下情况之一:
- 自独占读访问以来,该位置已被更新。
- 监控器已被重置到另一个位置。
- 主设备发出的独占读与独占写不具有相同的属性。
在所有这些情况下,独占写不得更新被寻址的位置,并且从属设备必须返回 OKAY 响应而不是 EXOKAY 响应。
如果一个不支持独占访问的从属设备收到独占写,它会返回一个 OKAY 响应,并且该位置会被更新。
8.4 原子事务
原子事务(Atomic transactions)执行的操作不仅仅是单一访问,它将一个操作与事务关联在一起。原子事务允许将操作发送到数据所在的位置,从而使得操作可以在离数据更近的地方执行。原子事务适用于数据与必须执行操作的代理之间距离很远的情况。
与使用独占访问相比,这种方法减少了数据必须对系统中其他代理不可访问的时间量。
8.4.1 概述
在一个原子事务中,主设备发送地址、控制信息和出站数据(outbound data)。从属设备发送入站数据(inbound data)(除了 AtomicStore)和响应。本规范支持四种形式的原子事务:
AtomicStore
- 主设备发送一个单一数据值,以及地址和要执行的原子操作。
- 从属设备使用发送的数据和地址位置处的当前值作为操作数来执行操作。
- 结果存储在地址位置。
- 给出一个不带数据的单一响应。
- 出站数据大小为 1、2、4 或 8 字节。
AtomicLoad
- 主设备发送一个单一数据值,以及地址和要执行的原子操作。
- 从属设备返回地址位置的原始数据值。
- 从属设备使用发送的数据和地址位置处的当前值作为操作数来执行操作。
- 结果存储在地址位置。
- 出站数据大小为 1、2、4 或 8 字节。
- 入站数据大小与出站数据大小相同。
AtomicSwap
- 主设备发送一个单一数据值和地址。
- 从属设备将地址位置的值与事务中提供的数据值进行交换。
- 从属设备返回地址位置的原始数据值。
- 出站数据大小为 1、2、4 或 8 字节。
- 入站数据大小与出站数据大小相同。
AtomicCompare
- 主设备向地址位置发送两个数据值:比较值(compare value)和交换值(swap value)。比较值和交换值的尺寸相等。
- 从属设备将地址位置的数据值与比较值进行检查:
- 如果值匹配,则将交换值写入地址位置。
- 如果值不匹配,则不写入交换值。
- 从属设备返回地址位置的原始数据值。
- 出站数据大小为 2、4、8、16 或 32 字节。
- 入站数据大小是出站数据大小的一半,因为出站数据包含比较值和交换值,而入站数据只有原始数据值。
8.4.2 原子事务操作
本规范支持八种不同的操作,可用于 AtomicStore 和 AtomicLoad 事务,如下表所示。
| 操作符 | 描述 |
|---|---|
ADD |
内存中的值与发送的数据相加,结果存储在内存中。 |
CLR |
发送数据中的每个置位(set bit),都清除内存中相应数据的对应位。 |
EOR |
发送的数据与内存中的值进行按位异或(exclusive OR)运算。 |
SET |
发送数据中的每个置位,都置位(sets)内存中相应数据的对应位。 |
SMAX |
存储在内存中的值是现有值和发送数据中的最大值。此操作假设数据为有符号。 |
SMIN |
存储在内存中的值是现有值和发送数据中的最小值。此操作假设数据为有符号。 |
UMAX |
存储在内存中的值是现有值和发送数据中的最大值。此操作假设数据为无符号。 |
UMIN |
存储在内存中的值是现有值和发送数据中的最小值。此操作假设数据为无符号。 |
8.4.3 原子事务属性
原子事务的规则如下:
AWLEN和AWSIZE指定事务中写数据的字节数。对于AtomicCompare,字节数必须同时包含比较值和交换值。- 如果
AWLEN指示事务长度大于 1,则AWSIZE必须是完整的数据通道宽度。 - 不在
AWADDR和AWSIZE指定的数据窗口内的写选通(write strobes),必须被置低(deasserted)。 - 在数据窗口内的写选通,必须被置高(asserted)。
对于 AtomicStore, AtomicLoad, 和 AtomicSwap:
- 写数据和读数据分别是 1、2、4 或 8 字节。
AWADDR必须对齐到总写数据大小。AWBURST必须是INCR。
对于 AtomicCompare:
- 写数据是 2、4、8、16 或 32 字节,读数据是 1、2、4、8 或 16 字节。
AWADDR必须对齐到总写数据大小的一半。- 如果
AWADDR指向事务的前半部分:- 比较值首先发送。对于单次传输事务,比较值位于较低字节;对于多次传输事务,比较值位于第一次传输中。
AWBURST必须是INCR。
- 如果
AWADDR指向事务的后半部分:- 交换值首先发送。对于单次传输事务,交换值位于较低字节;对于多次传输事务,交换值位于第一次传输中。
AWBURST必须是WRAP。
- 对于
WRAP类型的事务,协议对常规规则有所放宽:- 允许
Length为 1。 - 不要求
AWADDR对齐到传输大小。
- 允许
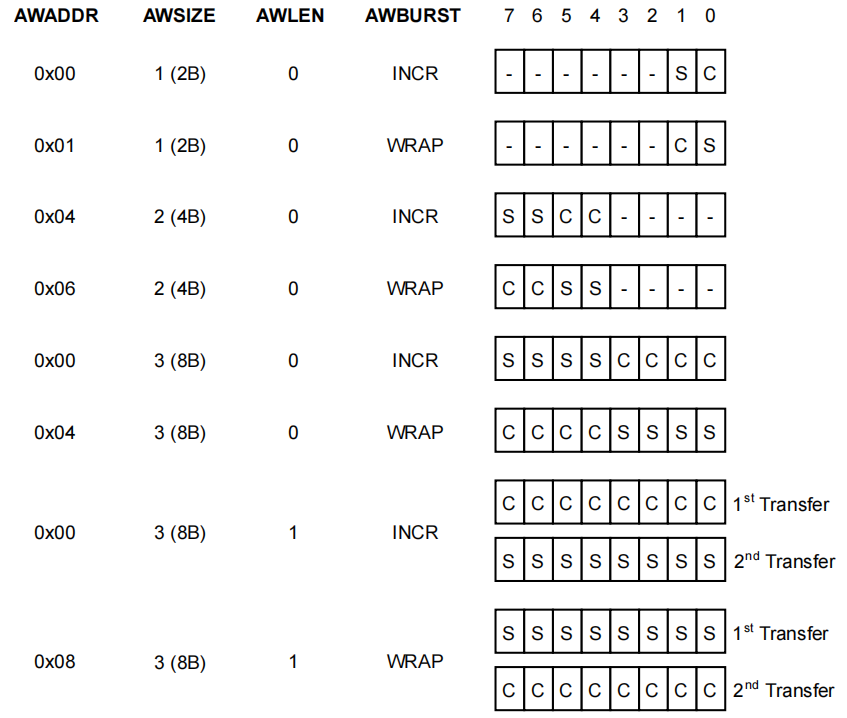
下图展示了数据通道为 64 位的 AtomicCompare 事务示例。
8.4.4 原子事务的 ID 使用
一个原子事务使用单个 AXI ID。请求、写响应和读数据都使用相同的 AXI ID。此要求意味着主设备只能使用那些可以在 AWID 和 RID 信号上都能进行信号传输的 ID 值。
原子事务不得使用与同时未完成的非原子事务所使用的 AXI ID 值。此规则适用于 AR 或 AW 通道上的事务。该规则确保了原子事务和非原子事务之间没有排序约束。
如果一个事务在另一个事务发出之前已完全完成,原子事务和非原子事务可以使用相同的 AXI ID 值。
同时未完成的多个原子事务不得使用相同的 AXI ID 值。
对于使用读数据通道的原子事务,如果接口包含唯一 ID 信号,那么如果 AWIDUNQ 被置高,RIDUNQ 也必须被置高。更多详细信息,请参见 6.2 唯一 ID 指示符。
8.4.5 原子事务的请求属性限制
对于原子事务,请求属性的以下限制适用:
AWCACHE和AWDOMAIN被允许是接口类型有效的任何组合。AWSNOOP必须设置为全零。如果AWSNOOP有任何其他值,AWATOP必须为全零。AWLOCK必须被置低,不能是独占访问。
8.4.6 原子事务信号
为了支持原子事务,AWATOP 被添加到接口中。
| 名称 | 宽度 | 默认值 | 描述 |
|---|---|---|---|
AWATOP |
6 | 0x00 |
指示原子事务的类型和字节序。 |
AWATOP 的编码如表所示。
AWATOP[5:0] |
描述 |
|---|---|
0b000000 |
非原子操作 |
0b01exxx |
AtomicStore |
0b10exxx |
AtomicLoad |
0b110000 |
AtomicSwap |
0b110001 |
AtomicCompare |
对于 AtomicStore 和 AtomicLoad 事务,AWATOP[3] 指示原子操作所需的字节序(endianness):
- 当置低时,该位指示操作是小端(little-endian)。
- 当置高时,该位指示操作是大端(big-endian)。
AWATOP[3] 的值仅适用于算术操作,对于按位逻辑操作则被忽略。
对于 AtomicStore 和 AtomicLoad 事务,下表显示了较低位 AWATOP[2:0] 信号的操作编码。
AWATOP[2:0] |
操作 | 描述 |
|---|---|---|
0b000 |
ADD |
加法 |
0b001 |
CLR |
位清零 |
0b010 |
EOR |
按位异或 |
0b011 |
SET |
位设置 |
0b100 |
SMAX |
有符号最大值 |
0b101 |
SMIN |
有符号最小值 |
0b110 |
UMAX |
无符号最大值 |
0b111 |
UMIN |
无符号最小值 |
8.4.7 事务结构
对于 AtomicLoad、AtomicSwap 和 AtomicCompare 事务,其事务结构如下:
- 请求在 AW 通道上发出。
- 相关的事务数据在 W 通道上发送。
- W 通道上所需的写数据传输次数由 AWLEN 信号决定。
- 原子事务请求和原子事务写数据的相对时序未指定。
- 从属设备使用 R 通道返回原始数据值。
- 读数据传输次数由 AWLEN 和 AWATOP 信号共同决定。对于 AtomicCompare 操作,如果 AWLEN 指示事务长度大于 1,则读数据传输次数是 AWLEN 指定次数的一半。
- 允许从属设备在发送读数据之前等待所有写数据。主设备必须能够在未收到任何读数据的情况下发送所有写数据。
- 允许从属设备在接受任何写数据之前发送所有读数据。主设备必须能够在未接受任何写数据的情况下接受所有读数据。
- 单个写响应在 B 通道上返回。从属设备必须在接收所有写数据传输且原子事务的结果可观察之后,才能给出写响应。
下图展示了 AtomicLoad、AtomicSwap 和 AtomicCompare 事务涉及的传输。
![]()
对于 AtomicStore 事务,其事务结构如下:
- 请求在 AW 通道上发出。
- 相关的事务数据在 W 通道上发送。
- W 通道上所需的写数据传输次数由 AWLEN 信号决定。
- 原子事务请求和原子事务写数据的相对时序未指定。
- 单个写响应在 B 通道上返回。从属设备必须在接收所有写数据传输且原子事务的结果可观察之后,才能给出写响应。
下图展示了 AtomicStore 事务涉及的传输。
![]()
8.4.8 响应信号
对原子事务的写响应表示该事务对所有必需的观察者是可见的。
包含读响应的原子事务从接收到第一项读数据开始,对所有必需的观察者是可见的。
主设备可以使用读响应或写响应作为事务对所有必需的观察者可见的指示。
没有与操作相关的错误概念,例如溢出。一个操作对于所有输入组合都是完全指定的。
对于像 AtomicCompare 这样的多结果事务,没有提供事务结果的指示。要确定 Compare and Swap 指令是否更新了内存位置,需要检查作为事务一部分返回的原始数据值。
当事务到达一个不支持原子事务的组件时,允许给出错误响应。
对于 AtomicLoad, AtomicSwap 和 AtomicCompare 事务:
- 即使写响应是
DECERR或SLVERR,从属设备也必须发送正确数量的读数据传输。 - 主设备可以忽略写响应,只使用随读数据一起返回的响应。
8.4.9 原子事务依赖
对于 AtomicLoad, AtomicSwap 和 AtomicCompare 事务,下图展示了以下原子事务握手信号依赖关系:
- 主设备在置高
AWVALID或WVALID之前,不必等待从属设备置高AWREADY或WREADY。 - 从属设备在置高
AWREADY之前,可以等待AWVALID或WVALID,或两者都置高。 - 从属设备可以在
AWVALID或WVALID,或两者都置高之前,置高AWREADY。 - 从属设备在置高
WREADY之前,可以等待AWVALID或WVALID,或两者都置高。 - 从属设备可以在
AWVALID或WVALID,或两者都置高之前,置高WREADY。 - 从属设备必须等待
AWVALID、AWREADY、WVALID和WREADY都置高之后,才能置高BVALID。 - 从属设备还必须等待
WLAST置高之后才能置高BVALID,因为写响应BRESP必须在写事务的最后一次数据传输之后才能发出信号。 - 从属设备在置高
BVALID之前,不必等待主设备置高BREADY。 - 主设备在置高
BREADY之前,可以等待BVALID。 - 主设备可以在
BVALID置高之前,置高BREADY。 - 从属设备必须等待
AWVALID和AWREADY都置高之后,才能置高RVALID以指示有效数据可用。 - 从属设备在置高
RVALID之前,不必等待主设备置高RREADY。 - 主设备在置高
RREADY之前,可以等待RVALID置高。 - 主设备可以在
RVALID置高之前,置高RREADY。 - 主设备在置高
WVALID之前,不必等待从属设备置高RVALID。 - 从属设备在置高
RVALID之前,可以等待所有写数据传输的WVALID置高。 - 主设备可以在
RVALID置高之前,置高WVALID。
在下图所示的依赖图中:
- 单头箭头指向的信号可以在箭头起始处的信号之前或之后置高。
- 双头箭头指向的信号必须在箭头起始处的信号置高之后才能置高。
![]()
8.4.10 对原子事务的支持
Atomic_Transactions 属性用于指示一个组件是否支持原子事务。
下表展示了 Atomic_Transactions 属性。
Atomic_Transactions |
默认值 | 描述 |
|---|---|---|
True |
支持原子事务。 | |
False |
Y | 不支持原子事务。 |
在某些实现中,这将是一个固定的接口属性,其他实现可能允许在设计时设置该属性。
如果一个从属设备或互连组件声明它支持原子事务,那么它必须支持所有操作类型、大小和字节序。
主设备支持
支持原子事务的主设备组件也可以包含一种机制来抑制原子事务的生成,以确保在不支持原子事务的系统中具有兼容性。
为此,指定了一个可选的 BROADCASTATOMIC 引脚。当该引脚存在且被置低时,主设备将不会从其接口发出原子事务。
下表展示了 BROADCASTATOMIC tie-off输入。
| 名称 | 宽度 | 默认值 | 描述 |
|---|---|---|---|
BROADCASTATOMIC |
1 | 0b1 |
主设备tie-off输入,用于控制从接口发出原子事务。 |
从属设备支持
从属设备组件支持原子事务是可选的。
如果一个从属设备组件只支持特定内存类型或特定地址区域的原子事务,那么对于它不支持的原子事务,从属设备必须给出适当的错误响应。
互连支持
互连支持原子事务是可选的。
如果一个互连不支持原子事务,所有连接的主设备组件必须被配置为不生成原子事务。
互连中支持原子事务的任何点都可以支持原子事务,包括将原子事务传递给下游的从属设备组件。
原子事务不要求在每个地址位置都得到支持。如果某个给定的地址位置不支持原子事务,则可以为该事务给出适当的错误响应。
对于设备(Device)事务,原子事务必须传递到终点从属设备。如果从属设备配置为指示它不支持原子事务,那么互连必须为此事务给出错误响应。原子事务不得传递给不支持原子事务的组件。
对于可缓存(Cacheable)事务,互连可以:
- 在互连内部执行原子操作。这种方法要求互连执行适当的读、写和监听事务来完成操作。
- 如果适当的终点从属设备配置为支持原子操作,那么互连可以将原子操作传递给从属设备。



